
Feed 流系统的架构设计方案
Feed流概述
定义与特点
Feed流是持续更新展示给用户的信息流(某种意义上来说,你可以一直向下滑动,而后获取到信息的应用都属于feed流),具有千人千面的个性化特点,如手机App中的猜你喜欢、关注和好友动态等。
与传统信息获取渠道(报纸电视)相比,Feed流可根据用户行为聚合信息(最核心的能力),以信息流方式提供给用户,降低获取信息难度,提升用户体验。
分类方式
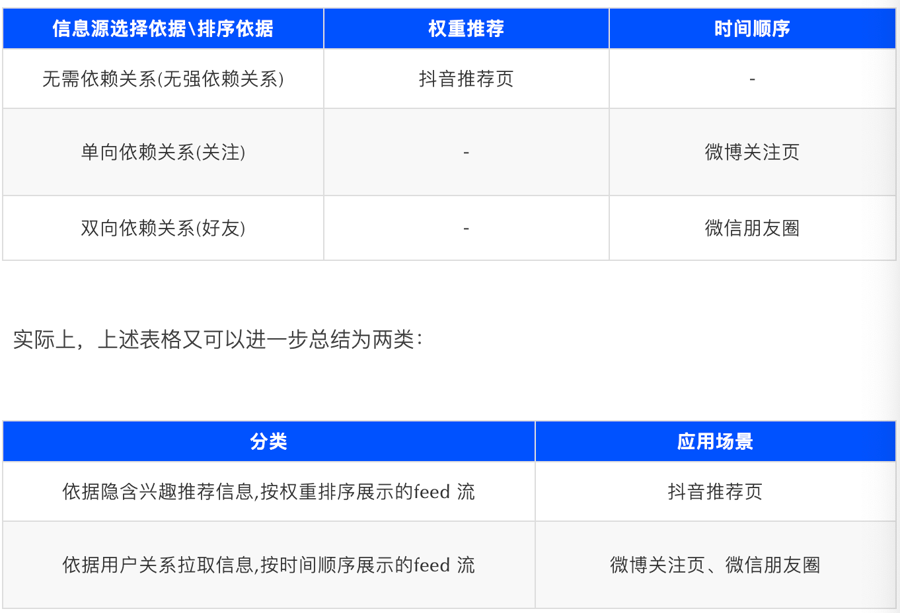
按信息源聚合依据:
无需依赖关系(如抖音推荐页,适用于信息探测)
单向依赖关系(如微博关注页,适用于信息订阅)
双向依赖关系(如微信朋友圈,适用于熟人社交)
按展示逻辑:
权重推荐(如抖音推荐页)
时间顺序展示(如微信朋友圈、微博关注页)
本质上可总结为依据隐含兴趣推荐信息按权重排序展示和依据用户关系拉取信息按时间顺序展示两类Feed流。
注意:微博热榜很多人也算成了 Feed 流,但是严格意义上来说,他是一个信息流。所有人看到的热榜数据都是一样的,这缺失了信息聚合的特征。所以,本质上热榜的底层模型应该是排行榜,而非 Feed 流。这里不将它归为一类。
发展历程
起源于RSS系统。RSS是一种更为传统的信息获取方式,它依赖于网站的更新;而Feed则更加现代和个性化,它依赖于用户关注的人或者团体的活动。
术语解释
Feed
Feed 流中的每一条状态或消息为 Feed,比朋友圈中的一个状态、微博中的一条微博
Feed 流
Feed流本质上是数据流,核心逻辑是服务端系统将 “多个发布者的信息内容” 通过 “关注收藏屏蔽等关系” 推送给 “多个接收者”。常见的,比如微博上的超话,新版本的微信公众号订阅消息,抖音里的视频流等等
三大特点:少部分人发布;基于订阅行为关联关系;大多数人读取信息
Timeline
Timeline是一种Feed流,微博,朋友圈都是Timeline类型的Feed流
又叫时间轴
关注页Timeline
展示其他人Feed消息的页面,比如朋友圈,微博的首页等。
又叫做收件箱,每个用户能看到的消息都会被存储到收件箱中
个人页Timeline
展示自己发送过的Feed消息的页面,比如微信中的相册,微博的个人页等
又叫做发件箱,自己发布的消息都会被记录到自己的发件箱中。别人的收件箱内的消息,也是从他的各个关注人的发件箱内同步过来的。
写扩散
一种消息同步方式,用户发布消息后,消息被记录到用户的发件箱中,此时立刻将发件箱内的消息同步给所有用户的收件箱。
又叫做推模式
读扩散
一种消息同步方式,用户发布消息后,消息被记录到用户的发件箱中。而消息的接收方此时没有收到消息。接收方按需(查看收件箱)拉取消息(所有关注人发件箱的消息),完成消息同步。
又叫做拉模式
Feed流模型架构
依赖用户关系的时间顺序Feed流
面临挑战:
**性能要求高:**需满足实时性,消息实时产生、消费和推送;
**存储要求大:**消息来源多且海量;
读写失衡模型:读写比大,性能考虑时间排序;
**原子性:**要求用户感知消息,保证最终一致性。
基本功能:
用户发布:用户可以发布一条消息,他的订阅者都能感知到他发布了消息
用户删除:
查看消息:查看自己发布的所有消息
订阅/取消订阅消息源:注意有的场景中要求用户 Feed 流中能看到博主在被关注之前发的消息,这就要求订阅的时候,还要主动同步一份博主的所有消息到用户的 Feed 流中。
查看Feed流
额外:支持黑白名单和评论功能等。
问题与解决方案
发布者与订阅者消息读取
一般采用写扩散:发布者发布消息后,将自己的消息同步给粉丝的收件箱。
大v用户采用读写结合
热粉丝写扩散,冷粉丝读扩散
冷热分离方案:根据登录次数、时长或session池判断在线情况
Feed流翻页
首先不能采取传统的 page_size 和 page_num,因为它是一个动态列表,每时每刻都有可能更新,如果两页之间出现内容的添加或删除,都会导致错位问题。
使用last_id记录上一页最后一条内容的id,避免传统分页方式在内容更新时的错位问题。
写扩散下last_id直接往后读取
读扩散下需记录拉取的write_last_id(多少个关注就记录多少个write_last_id),翻页时根据write_last_id往后拉取新的一定量(比如 page_size 个)的数据,再用这些数据组成新的收件箱列表,筛选page_size返回前端,同时更新write_last_id。
由此可见:读扩散的翻页比写扩散复杂很多-。-
写扩散模式下删除修改问题
采用软删除(置为删除状态,查询时过滤)和懒删除(过滤时从收件箱真正删除)机制,通过读扩散回查方案,只写消息id到收件箱,查询时再丰富信息(比直接把内容一起写入收件箱内会更加节约内存,减少冗余数据,同时消息删除无需扩散)。
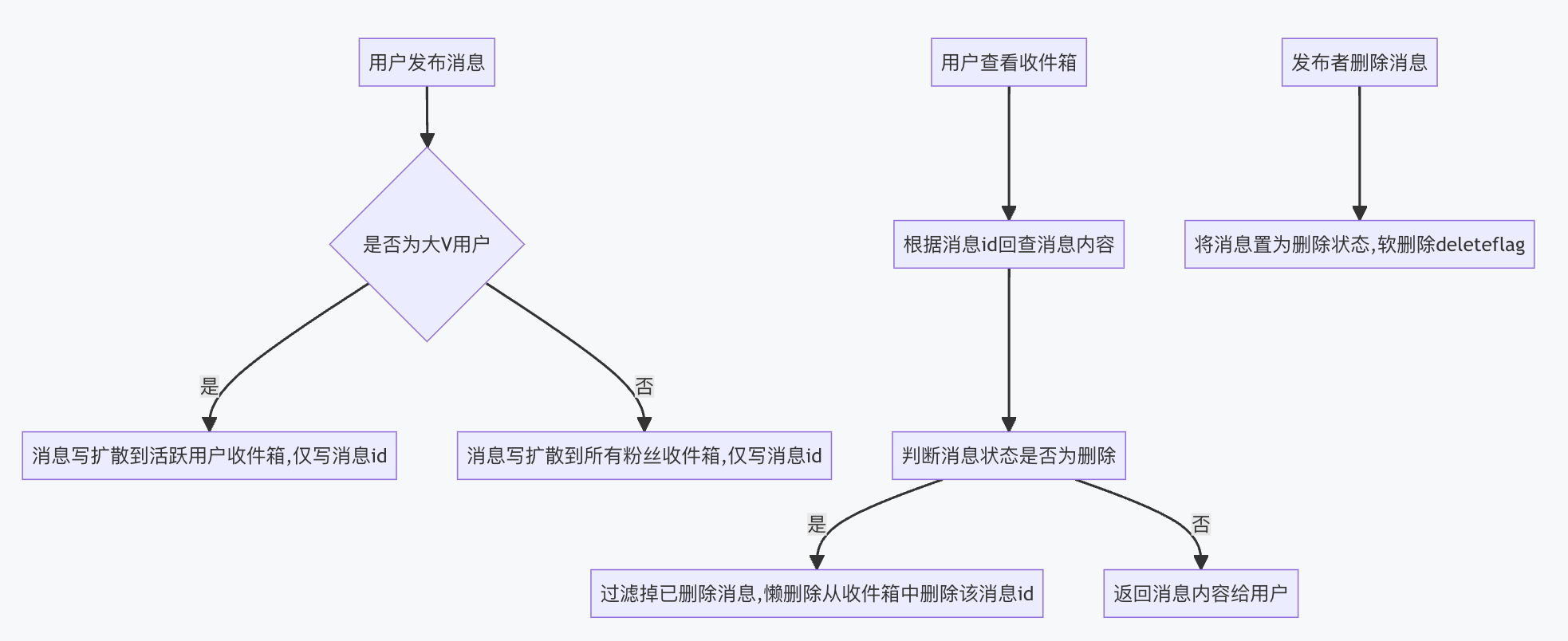
用户收件箱刷新时机
关注他人时采用写扩散+刷新(也就是获取到关注用户的发件箱内所有消息,然后刷新自己的收件箱)
取消关注、关注人删除或修改消息时采用读扩散+懒删除方式,通过回查过滤完成同步。
不同的业务场景会遇到不同的侧重点,上述方案仅仅是一个参考。
总体设计
架构设计
系统包括消息发送逻辑、用户操作触发、对外CGI模块、消息队列等
通过抽象数据结构(消息、消息发布处理器、用户、发布配置)
设计良好的数据库表(消息表、收件箱、发布配置表、关注关系表)来满足性能要求
核心难点是发布和拉取Feed流功能。

存储和缓存设计
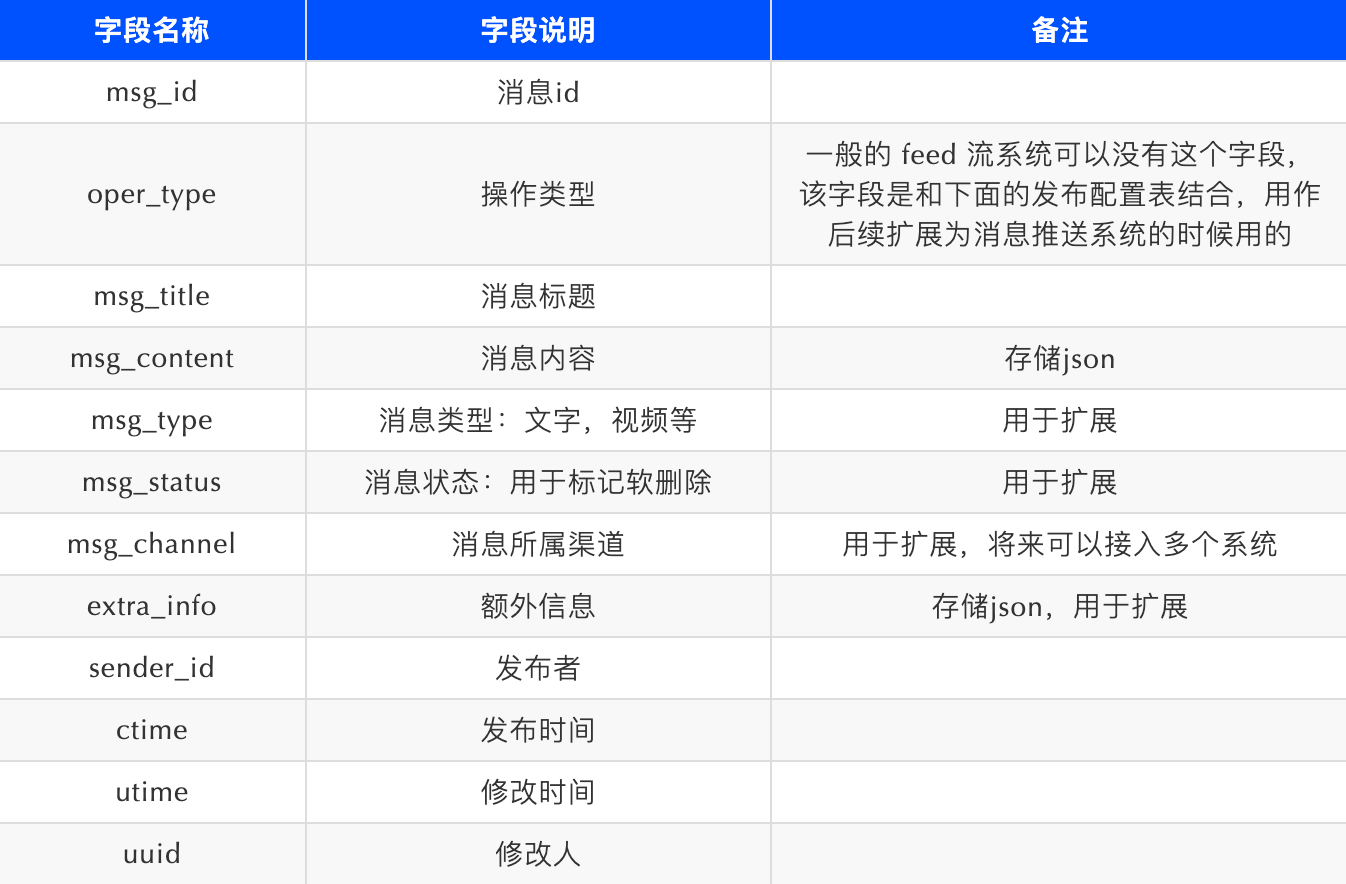
消息表:存储消息相关信息,如id、标题、内容、类型、状态、渠道、发布者、时间等,部分字段用于扩展。
收件箱:采用redis的zset存储,key为接收者uid + channelid,value为发件人uid + 消息id,score为发布时间戳,可实现自动排序。
发布配置表:用于扩展为消息推送系统,包含发布id、类型、规则、渠道等信息。

关注关系表:记录博主与粉丝关系,包括uid、状态、热粉丝标记等,用于粉丝冷热分离查询优化。

核心业务流程
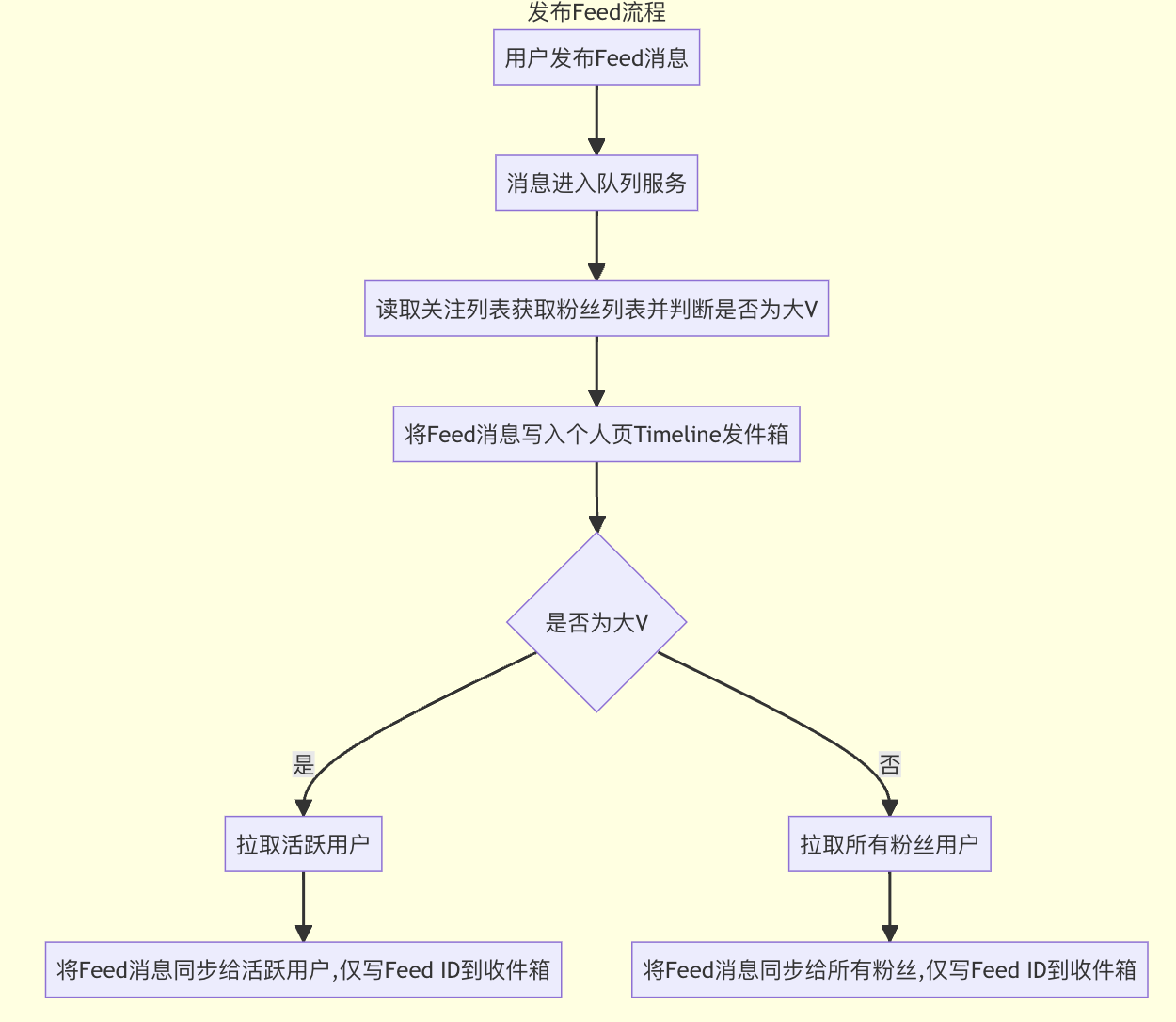
发布Feed流程:
消息进入队列
读取粉丝列表,判断自己是否为大v
把feed写入个人页Timeline(发件箱)
大V拉取活跃用户、普通用户拉取所有粉丝,同步Feed ID给粉丝。
读取Feed流流程:
判断自己是否为活跃用户,不是的话才去读扩散,读取自己关注的大v列表
读取收件箱(起始位置为上次最新Feed ID)并反查剔除软删除数据,
非活跃用户,并发读取关注的大V列表的发件箱
合并结果排序后返回给用户。
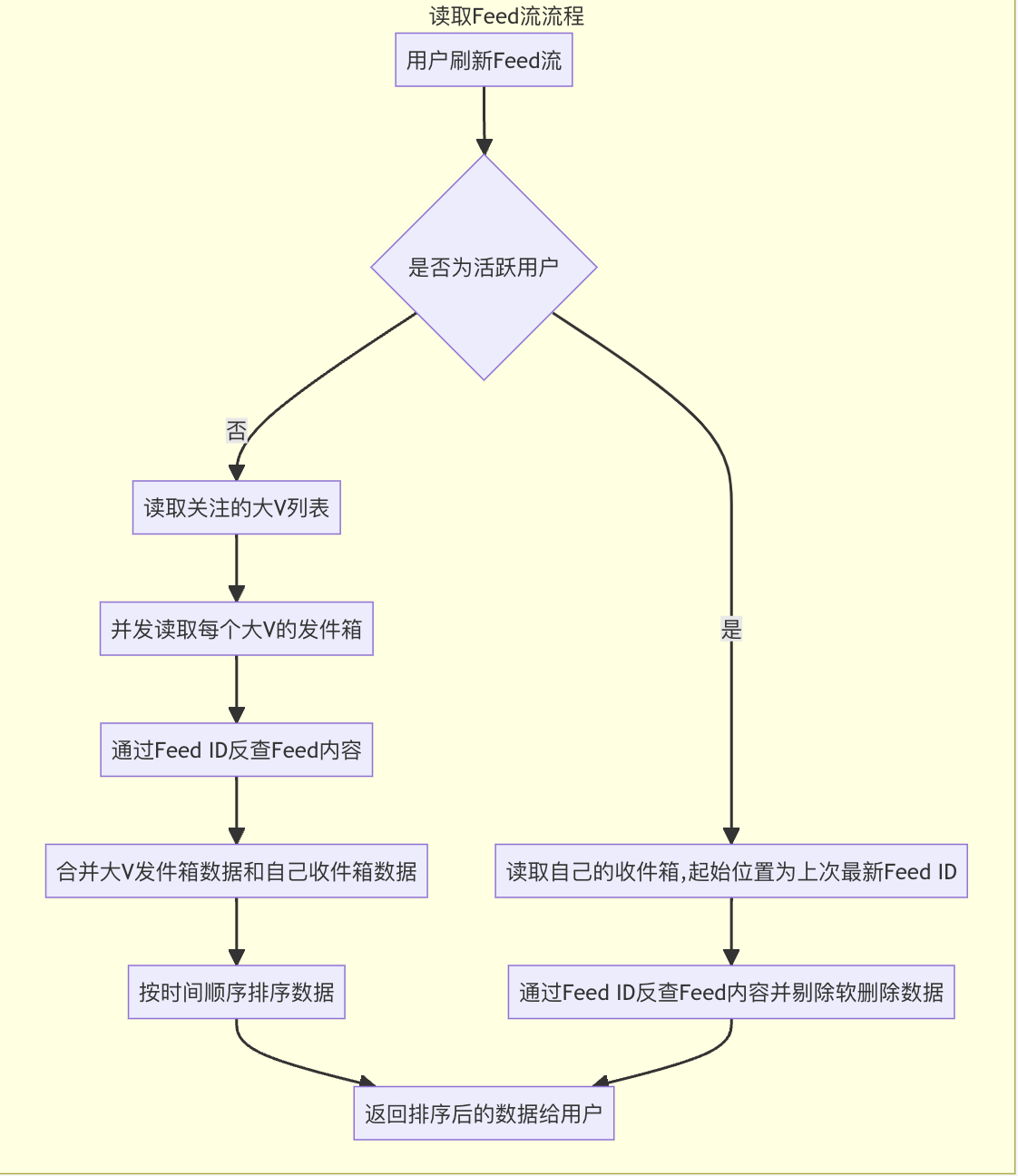
至此,使用推拉结合,冷热分离方式的 Feed 流发布,读取 Feed 流的流程都结束了。
最后更新于